近幾年來人工智慧(Artificial Intelligence, AI)喴的震天價響,吃也要AI,穿也要AI,連上個廁所也要來個AI智能健康分析,生活週遭食衣住行育樂幾乎無處不AI,彷彿已經來到科幻電影中的那個世界,面對這波「智能」新浪潮,身為Maker的我們自然不能缺席。本文將完整介紹AI晶片的發展,以及Maker們如何使用AI晶片與創作接軌。
AI這個領域看似深不可測,大家都說你得先學個線性代數、機率再加上一堆理論以及看了就頭疼的程式碼,再經過數年修練,就能小有成就。不過,大家請不必擔心,這些難的部份就先交給聰明的資料科學家和工程師,Maker們只要應用他們開發出的源碼及工具(SDK) 發揮創意專心創作出更具「智能化」的作品,解決更多人們的需求即可。
打個比方,「就像學開車不必先懂得車子如何設計,只需到駕訓班學基本原理、操作及交通安全規則就可上路了。」但是,如果你想精進駕駛技術,甚至當個專業賽車手或開發出專屬的車子,這時就必須更了解車子的設計原理,並學著如何改車及用何種方式駕駛,如此才能發揮車子的最大效能。

AI的應用不難,但想精通就得好好修練,就像除了知道怎麼開車以外,還需要知道車子的原理與架構
從開車的例子來舉例:AI晶片就如同引擎,計算能力等同於決定車子的馬力,而算法(模型)就像車型,不同的車型有著不同用途、解決不同的問題,如果開著跑車要載貨而開著貨車要競速,相信一定不會有好的結果。而大量的資料就像汽油,少了它車子肯定動不了。
接下來就從當下最熱門的議題「人工智慧晶片(AI Chip)」來切入,讓大家能更進一步了解AI基本術語及觀念,各家AI晶片技術到底有何不同及Maker們要如何運用這些資源來提升創作使其更智能化。
人工智慧與深度學習
自1950年代「人工智慧」一詞被提出,但受限於硬體計算能力、算法可用性及資料集的數量,幾經浮沈始終未能推出實用的結果。直到2012年Alex Krizhevsky 利用深度卷積神經網路(Deep Convolutional Neural Network, CNN)以大幅差距贏得知名影像分類ILSVRC大賽,大家才重新對人工智慧重燃起希望。
2016年Google的「Alpha Go」完勝最難攻克的圍棋,更是激起各國政府及普羅大眾對人工智慧的重視。聽到「人工智慧」這個名詞,相信大家腦中一定浮現各種科幻電影的場景,想像著電腦已經可以取代人類完成各種需要大量思考才能完成的事,但現實上並非如此。

2016年 Alphago 圍棋競賽
目前市面上說的人工智慧,大多是指深度學習(Deep Learning, DL)算法所產生的結果,其實只是在找一個最佳函數解,而非真正具有像人的思考方式。
更進一步來說,如下圖所示(Fig. 1),人工智慧包含了機器學習(Machine Learning, ML),而其下又包含了有標準答案才能學習(訓練)的監督式(Supervised)學習(分類、迴歸),沒有標準答案可自動依資料屬性分群的非監督(Unsupervised)式學習(聚類)及具獎懲機制找出最佳答案的增強式(Reforcement)學習(分類)。
深度學習只是由監督式學習下的神經網路(Neural Network, NN)所演化出來的,經過這幾年不斷的演化,目前已從只能處理監督式學習問題擴展到非監督式及增強式學習。因此,目前市售的AI晶片發展趨勢多半鎖定在處理深度學習類型問題,而非處理傳統機器學習及真正人工智慧的問題。
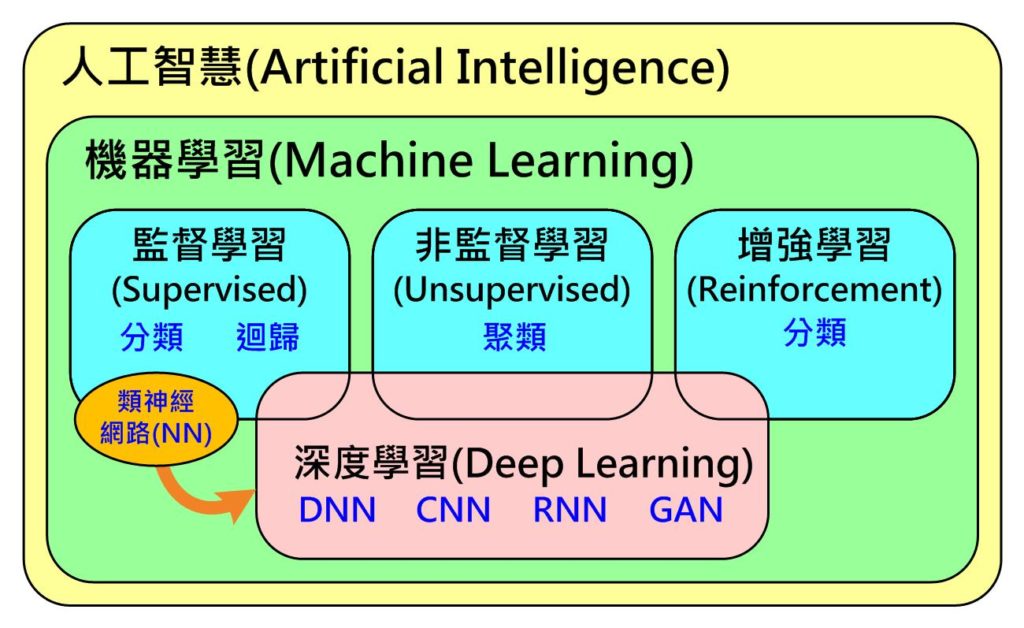
Fig. 1 人工智慧、機器學習與深度學習關係 (圖片來源:OmniXRI整理繪製)
深度學習技術的應用
目前應用人工智慧或者更精準地說,深度學習到底能解決什麼問題呢?最常見的兩大領域就是影像及語音
在影像方面,可對單張影像進行單一項目分類( Fig. 2a),但若影像中,同時出現二種類型物件時,那就很有可能分類錯誤或者同時歸屬到多個類別中。再來,可找出影像中多個物件並定位出來( Fig. 2b)。
若想要再更精準描繪出物件輪廓就必須進行語義分割(Fig. 2c),換句話說就是以像素等級的方式進行分類,把每個像素分到指定的分類中,此時仍無法區分出相同物件不同個體。最高等級就是實例分割(Fig.2 d),不僅能精準分割物件輪廓且能分割出不同個體。當然,這四類型的難度也是依序提高,所需付出的計算量也相對提高。

Fig. 2 常見影像應用人工智慧使用情境 (圖片來源:OmniXRI整理繪製)
另一個較大應用的領域就是「語音」,首先要讓電腦聽懂我們在說什麼,就必須正確地把語音變成文字(Fig. 3e),才能提供給後續的語言(意圖)解讀(Fig. 3g)。當然要聽懂是誰在說話,而說話的情緒為何也是很重要的(Fig. 3f),在了解說話的內容後就必須產生回答,把通順的句子合成為柔美的語音(Fig. 3h),才能完成一個完整的對話過程,不然就變成雞同鴨講。
除此之外,如文章翻譯、影片摘要、股市分析、交通物流、醫療照護等,非影音領域的應用也都很適合以深度學習方式進行辨識及分析。
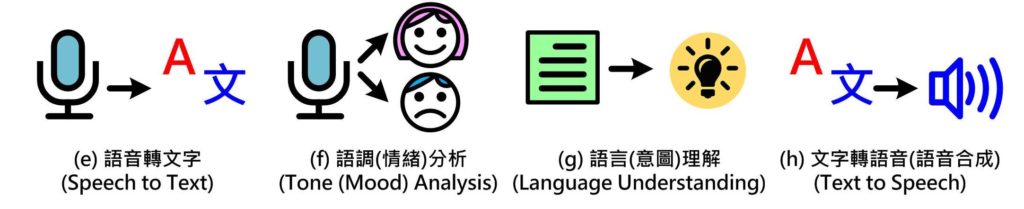
Fig. 3 常見語音應用人工智慧使用情境 (圖片來源:OmniXRI整理繪製)
AI晶片的神經網路(NN)工作原理
為了能更進一步了解以深度學習為主的AI晶片到底要如何工作,首先要了解組成「神經網路(NN)」神經元的工作原理。
如下圖(Fig. 4a)所示,每個神經元有n個輸入值,每個輸入值有一個權重(Weight)值,把所有輸入值乘權重值加總起來,有時會另外加上一個偏置值(Bias)來調整,將得到的值再經過一個激活函數(Activation function)即可產生新的輸出值。從另一個角度來看,相當於每個權重值決定對應的輸入值對這個神經元的影響程度。
以Fig. 4a為例,由左至右為推論(Inference),可得到算輸出結果,過程中需要n個權重值加上1個偏置值,而這些值是需要經由訓練(Training)而得。訓練前須取得許多(越多越好)已知答案或稱為標籤(Label)的訓練資料,假設輸出值只有二種答案,是(1.0)或者不是(0.0)。
如果第一組輸入資料已知答案為是(1.0),但經過推論後只得到0.6,則表示權重及偏置值不理想需要調整,此時利用根據差值(1.0 – 0.6 = 0.4)由右至左調整每個權重及偏置值,而至於調多少則隨不同方式也有不同。
同樣的步驟再輸入第二組資料進行調整,直到所有訓練資料都做過一輪(Epoch)。此時,大家可能會問這樣就訓練好了嗎?我們還得拿出另一組未曾出現在訓練資料中,但卻已知答案的資料來進行驗證,就如同學校老師教了許多內容,但要透過考試成績才能知道學生是否學會了,如果分數不及格,就要重新訓練加強磨練。
相同地,我們必須反覆執行這些步驟直到驗證資料都得到滿意的答案,因此,可想而知所需來回的次數相當大,所以通常訓練會需要設計什麼時候停止,可選擇成績(正確率)到達某個門檻,或者不管成績只考慮訓練次數。這就好比學校的模擬考,雖然學生每次都考高分,但真正考試時成績仍不理想,此時就得增加學習樣本重新訓練。
為了能處理更複雜的問題,一個神經元可擴展成一組簡單(單層)神經網路,如Fig. 4b所示,會有輸入層、隱藏層(Hidden Layer)及輸出層,推論及訓練的概念和一個神經元大致相同。若待解決問題更困難,如Fig. 4c所示,則可增加每一層的神經元或隱藏層數來解決。
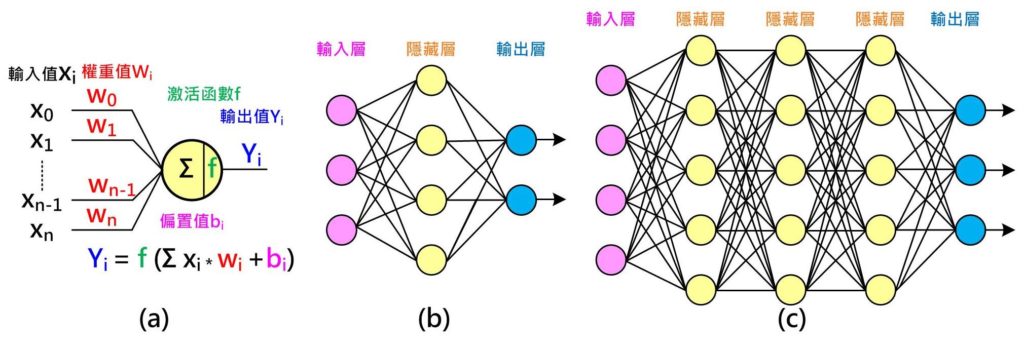
Fig. 4 神經網路:(a)神經元工作原理;(b)簡單(單層)神經網路;(c)複雜(深層)神經網路 (圖片來源:OmniXRI整理繪製)
深度學習的代表作 – 卷積神經網路(CNN)
不過,問題來了,當輸入的資料為影像時,隨便一張32*32的單色灰階影像,就有高達1024個輸入;若是彩色影像還要乘以三倍(R,G,B),如此龐大的網路,參數(權重、偏重值)數量實在多到難以計算。於是深度學習的代表作「卷積神經網路(CNN)」因此誕生了。
如 Fig. 5 所示,這是一個用來辨識手寫數字(0~9)的案例(模型),稱為「LeNet」,輸入為32*32點單色灰階影像,輸出為0~9的機率。其中應用到一種名稱「卷積」或「迴旋積」的技巧,它讓權重值可以共用,在 Fig. 5中顯示的 C1層就是由六組 5*5的卷積核計算後的結果,則只需156((5*5+1)*6)個參數就夠了。當輸入點數降低到夠少點數時再採用全連結(Full Connection)方式(如上圖Fig. 4a, 4b),Fig. 5中的F6層。不過即便是如此,LeNet整個完整網路仍有六萬個參數需要進行訓練。
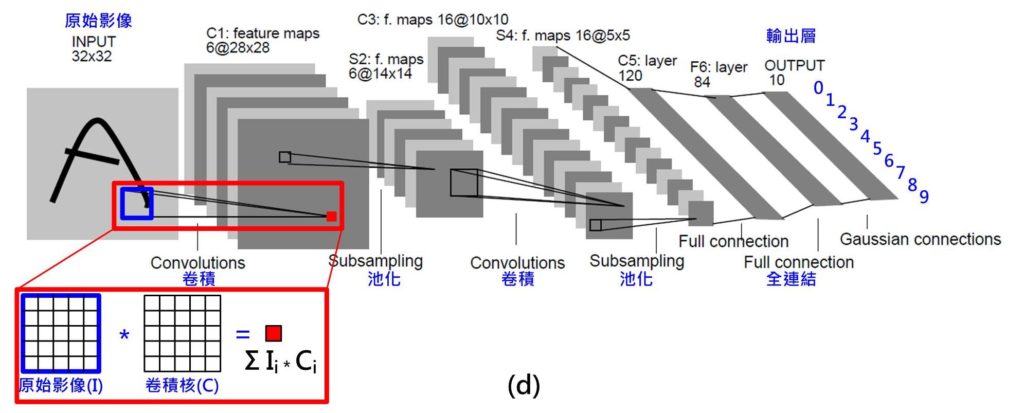
Fig. 5 神經網路:卷積神經網路(CNN, LeNet) (圖片來源:OmniXRI整理繪製)
為了解決各種不同問題,於是各種不同的網路(Net)結構或模型(Model)被提出。從Fig. 6 中可看出,橫軸是計算量,每個乘法或加法就算一次運算(Operations, Ops),不同算法從數千萬次到數百億次的計算才能推論一筆資料,通常計算量和參數量(圓圈直徑)有直接關係,參數量可能從數百萬到數億個。不過正確率和參數量及計算量則不一定有直接關連,對實際使用上來說當然希望找到計算量越低、正確率越高的模型,而正是AI科學家及工程師努力的方向。
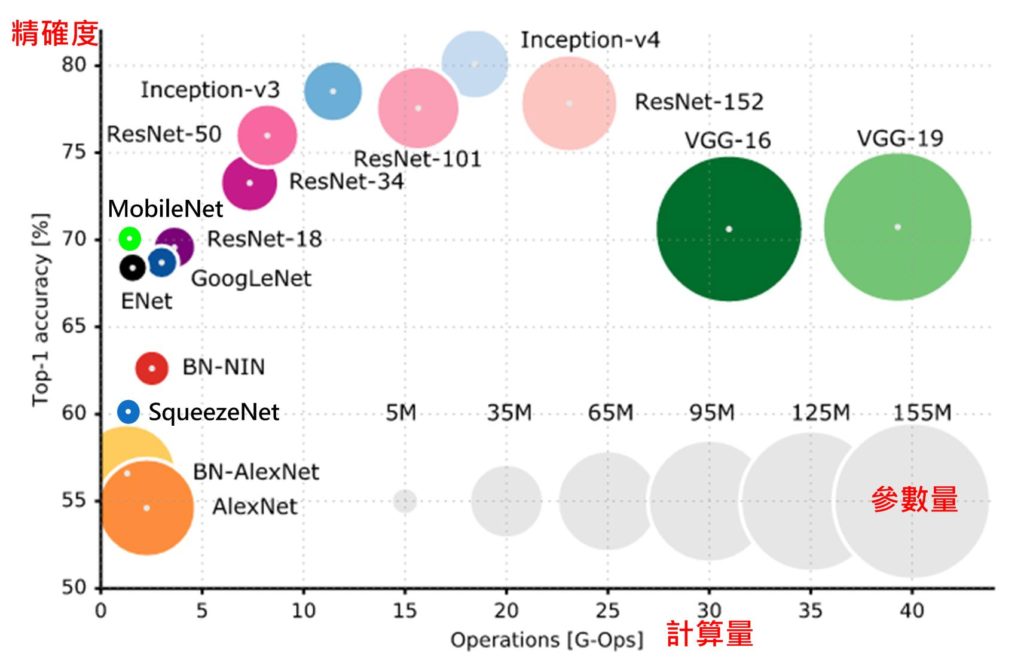
對Maker而言只需根據需求(正確率、計算量)及計算時間找到一個夠用的的模型及硬體平台(AI晶片)來用即可,就像只有幾個紙箱的東西要搬,不必找一台貨櫃車或一台千萬跑車來載。反之應用上若很在意正確率,則可能就要多浪費一些計算量(時間)及昂貴的硬體平台來換。
由上述內容可知雖然運用深度學習神經網路可得到較理想的辨識結果,但所需付出的代價也同樣非常驚人,光推論一筆資料就要計算數千萬次到數百億次,更不要說訓練時要訓練數萬到數百萬筆資料,數十到數千次循環週期(Epoch),所以如何加速訓練及推論時間就成了最重要的工作。
為了完成這麼龐大的工作,就必須有強悍運算能力的硬體平台。接著將詳細介紹目前市面上的各類AI晶片,進一步分析不同類型的晶片。
目前市面上對人工智能(AI)晶片常見的作法大致可分成五大類:通用型的CPU (Central Processing Unit)、半通用型的GPU (Graphics Processing Unit)、半專用型的FPGA (Field Programmable Gate Array)、專用型的ASIC (Application Specific Integrated Circuit)及混合型的SoC(System on ChiP),如下圖所示。接下來就針對各類型特色、代表性廠商及產品做一簡介,更完整的比較表請參考文末的比較表。
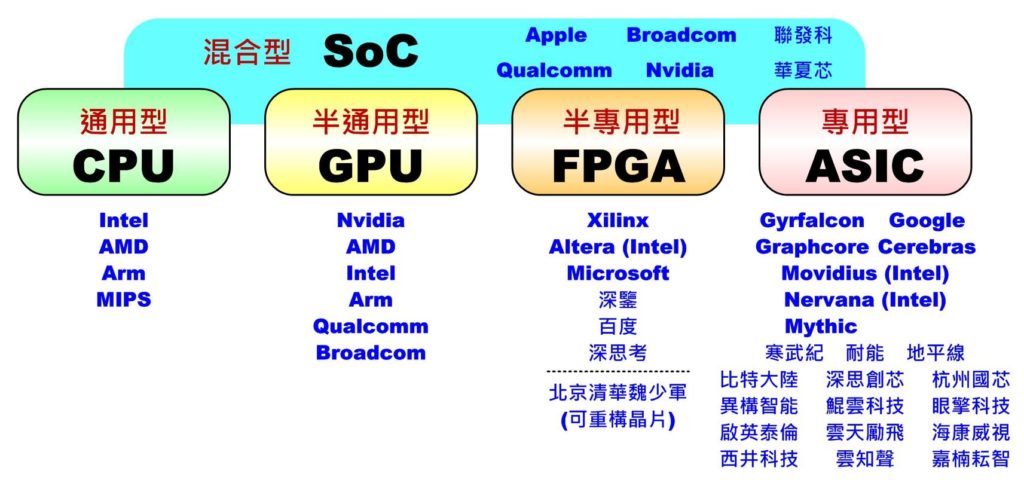
人工智能(AI)晶片主要分類及對應供應商(OmniXRI整理繪製)
一、中央處理器(CPU)─ 通用型AI晶片
一般電腦中一定會有CPU負責算術、邏輯、儲存及輸出入介面管理,因此可執行任何需要的演算法,當然也包括各式人工智慧、機器學習及深度學習的算法。其優點時可應付各種演算法的變化,彈性極高,並可處理邏輯運算及大量記憶體管理。現在較高階的CPU通常都會包含以往DSP(Digital Signal Processor)才有的乘加(MAC)指令,讓Y=A*B+C本來要兩次運算才能完成的指令,變成一次指令週期就能完成計算,加快運算速度。
但缺點是CPU計算用的核心(或執行緒Thread)數通常不會太多(一般型約1~10核,伺服器型32~72核),耗能較大,且未來核心數及速度已快達物理極限不易大幅提升,因此若要應付像深度學習這類大量演算時,通常只能選用核心(執行緒)數量較多或速度較快的晶片來解決,或者只執行較簡單模型的推論工作而不參與訓練。

此類型較具代表的廠商有Intel、AMD、ARM、MIPS等(後兩家不生產實體晶片僅提供矽智財,都已被併購)。在AI應用上,Intel和AMD比較著重提供伺服器等級的高效晶片,如Intel Xeon Phi 7290F或AMD EPYC 7601都是屬於高核心數、多執行緒型。而ARM和MIPS則在移動式或嵌入式平台較為常見,通常會搭配其它AI晶片一起執行。若只單純使用多核CPU進行運算時,則通常僅能執行較簡單的網路(模型)。
二、繪圖晶片(GPU)─ 半通用型AI晶片
繪圖晶片原來是用於處理3D模型大量的三角面繪製、著色及顯示,幾乎都在處理矩陣演算(乘加運算),沒有邏輯處理,因此設計上有大量(數百到數萬個)的計算核心可供平行運算。後來,有人發現此特性比CPU更有利於進行有大量矩陣的科學計算,於是推出類似OpenGL的通用式的描述式語言,忽略繪圖功能,直接當成平行運算使用,如GPGPU(General-purpose computing on graphics processing units)、OpenMP、OpenVx、CUDA(Nvidia專用)、 OpenCL(大多數繪圖晶片)、 Android NN等。
當深度卷積網路興起時,GPU正好滿足這項大量平行矩陣計算的需求,因此造成洛陽紙貴,高階顯示卡一卡難求。雖然GPU非常適合當作訓練用,且可適用各種新的網路的開發,但不適合具有大量邏輯判斷的算法,且浪費許多時間及功耗在處理繪圖流水線(Pipeline)。另外,許多深度學習的框架(例如:PyTorch、Caffe、TensorFlow、Mxnet、CNTK、Keras等)不一定對所有的GPU都有支援,尤其是對行動裝置上的GPU更常遇到無法直接使用的問題。

此類晶片最具代表性的廠商就是Nvidia,不但有完整的產品線(GeForce、 Tesla、Titan、DGX、Tegra、DriverPX等系列),從一般電腦、專業伺服器到嵌入式甚至自駕車都有對應產品,專業顯卡少則數千元,多則數百萬元。開發工具有CUDA, cuDNN等,更是促使GPU在AI應用上發揮更大算力,同時支援最多種深度學習框架,有完整的開發者生態圈,是其它GPU廠商難以憾動的。
雖然像AMD(Radeon系列)、Intel (HD Graphics系列)等大廠也有生產GPU,但目前可支援的框架就明顯少了許多。另外,在行動裝置上 Arm Mali系列、Qualcomm Adreno系列等較高階的可以用OpenCL來協助,但像Broadcom VideoCore系列就完全沒有框架可支援。
三、現場可程式邏輯閘陣列(FPGA)─ 半專用型AI晶片
GPU雖然使用上彈性較大,但畢竟不是專門用來做深度學習用的,有很長的工作流水線,所以在即時性、功耗及邏輯運算及記憶體管理等問題上都不易克服。如果設計成深度學習專用的積體電路(IC)又怕算法(模型)一直在演進,那好不容易才完成的IC就沒用了。一般IC設計完成後就不能變動,就像只能燒錄一次的光碟片,但FPGA卻允許隨時依需求變動,就像可重覆燒寫的光碟片,這項特性很適合在這個AI百家爭鳴的時代隨時可跟著一起演進又能保持執行效能。
不過這種方案最大的缺點是硬體成本很高,所以只適合放在機房當雲端訓練及推論用。此外由於記憶體不像CPU或GPU可以配置很大,所以並不適合參數量過大的模型。
目前Xilinx佔了約50%的市佔率,而深鑒科技(DeePhi)則主攻使用Xilinx Zynq 7000系列FPGA設計各種深度學習計算所需算法及開發工具,應用於無人機、安防、自駕車上,目前已獲多家知名創投投資。百度也利用Xilinx FPGA開發出XPU打造自家雲計算所需硬體。深思考(ideepwise)也利用FPGA製作專屬的AI晶片,鎖定醫療、情緒、自然語言、計算機視覺等領域。

而Intel為了補足在AI晶片市場的不足,於是在2015年把市佔率40%的Altera買下。而微軟則另闢戰場,花了六年時間執行Catapult計畫將FPGA全面進駐至Azure雲端資料中心加速AI相關服務的計算速度。另外為了讓IC設計人員能對AI領域算法快速上手,Xilinx已開始把常用的AI算法(模型)及影像辨識功能以模組(xfDNN, xfOpenCV)方式導入,相信未來會有更多專門用於AI領域的FPGA快速開發工具會加入戰場。
四、特殊應用積體電路(ASIC)─ 專用型AI晶片
為了展現更好的計算效能、更低的價格及功耗並兼容CPU和GPU的優點,設計出專屬於深度學習的AI晶片就變成不可或缺的。但此類專用型IC缺點就是沒有彈性,只能處理單一功能,所以為了應付AI算法(模式)不斷演化,多半會搭配特定框架(例如:TensorFlow, Cafee, MXNet等)進行開發,甚至更窄化到只針對大量矩陣演算的優化。另外由於ASIC投產所需成本極高,若一年沒有賣個數百萬到千萬台的銷量,則可能難以支付開發成本。
所以目前主要市場可分為用於機房雲端訓練及推論用、行動通訊裝置本地(邊緣)端(Local/Edge)推論用及特殊用途小型嵌入式裝置(如自駕車)等。因此為了吸引市場的目光,許多廠商紛紛推出各種新名詞來突顯自家的能力,比方說Google的TPU (Tensor Processing Unit)、Movidius(Intel收購)的VPU(Vision Processing Unit)、寒武紀(Cambricon)的NPU(Neural Processing Unit)、聯發科(MediaTek)的APU(Artificial intelligence Processing Unit)、地平線(horizon-robotics)的BPU(Brain Processing Unit)、深鑒(DeePhi)的DPU(Deep Learning Processor Unit)、Graphcore的IPU(Intelligence Processing Unit)。

Google推TPU AI晶片
另外像Mobileye更將自家專用於自駕車的EyeQ系列中的平行運算單元依不同用途細分為VMP(Vector Microcode Processors)、PMA (Programmable Macro Array)、MPC(Multithreaded Processing Clusters)。不管名稱為何,其本質都大同小異,都是在處理大量的矩陣平行演算。
為了使深度學習能普及到各種行動裝置並免除雲端連線計算即時性不佳的問題,此類專門用於推論的ASIC已成了兵家必爭之地,目前仍以影像及語音兩大領域應用為主,另外像人臉(生物)辨識、自駕車、智慧零售、智能拍照、安全監控、智能音箱、機器人、無人機、實境(VR/AR/MR/XR)互動等應用也是熱門領域。
五、系統級晶片(SoC)─混合型AI晶片
一般以CPU為主的小型嵌入式系統或是行動通訊裝置為了省電通常沒有太強大的計算能力,所以如果要順利執行人工智慧或深度學習相關應用,通常要搭配其它AI晶片才能順暢運作。較常見的作法是將多種功能直接整合到單一晶片上,或者稱為SoC(System on Chip),尤其手機、嵌入式裝置、物聯網(IoT)晶片幾乎都是採用此種作法。
舉例來說:
舉例來說:
1.Qualcomm的驍龍(Snapdragon) 845就包含8核CPU (Arm Cortex A75 * 4 + A55 * 4)、DSP (Hexagon 685)(AI用) 、Adreno 630 (GPU, VPU, DPU)(繪圖及影像處理用)。
2.Samsung的Exynos 9810包含8核CPU(四核客制+Arm Cortex A75 * 4)、18核GPU (Arm Mali G72-MP18)(繪圖顯示用)。
3.華為海思的麒麟(Kirin) 970包含8核CPU、12核GPU(Arm Mali G72-MP18)(繪圖顯示用)、雙ISP (影像影處用)、NPU (AI用)。
4.Apple的A11 Bionic包含6核CPU(Monsoon * 2 + Mistral * 4)、3核GPU (繪圖顯示用)、ISP (影像處理用)及具有0.6T Ops計算能力的Neural Engine (AI用)。
5.聯發科曦力(Helio) P60包含8核CPU(Arm Cortex-A73 * 4 + Arm Cortex-A53 *4)、GPU (Arm Mali-G72 MP3)、3核ISP,另外提供NeuroPilot開發平台串接CPU、GPU協同進行AI相關運算。

六、AI應用─自駕車領域
另外像自駕車領域的AI應用對於整合性、計算的即時性要求更高,因此通常都也會採混合式AI晶片設計。
舉例來說 :
舉例來說 :
1.Mobileye(Intel收購)的EyeQ4包含5核CPU(MIPS *4 + MIPS M5150 *1)、6核VMP、2核PMA、2核MPC,相當2.5TFlops的計算能力。
2.Nvidia TX2包含4核CPU(Arm Cortex A57 * 2 + Nvidia Denver 2 * 2)、GPU(Nvidia Pascal, 256 Cuda Core)。(主要用於空拍機及簡易車用)
3.Nvidia Drive PX Pegasus包含16核CPU(Nvidia Carmel)、4 組512 Cuda核GPU (NvidiaVolta iGPU * 2 + Nvidia post-Volta dGPU * 2),有320TOps的計算能力。
台灣目前僅有聯發科用了ARM的解決方案,開發出手機用SoC AI晶片Helio P60準備上市外,其它廠商可能都還在努力中或者只利用別家的AI晶片開發相關服務。相較於大陸已有十多家IC設計公司成功將產品上市,並且有眾多的AI晶片應用公司提供橫跨上、中、下游的服務,看來台灣得更加努力發揮創意突破這一困境了。
除此之外,目前還有幾家已被巨額投資但還未有產品上市的AI晶片公司也值得期待,如Intel收購的Nervana Systems、 知名創投Benchmark Capital投資的Cerebras Systems、SoftBank Ventures投資的Mythic,八位Google TPU團隊離職後開的公司Groq。

綜合以上內容,CPU(伺服器等級)、GPU、FPGA、ASIC等AI晶片都很適合大量建置在機房中,有利於雲端訓練及雲端推論,但行動裝置(邊緣計算)受限於產品體積大小、運算效能、消耗功率、產品價格等問題,通常要採用ASIC或SoC類型的AI晶片,而訓練部份就得仰賴雲端訓練後再將參數值下載到行動裝置中進行推論。
至於全球AI晶片廠商產品的比較,請參考下表(本表頗長,點擊圖可完整觀看)。
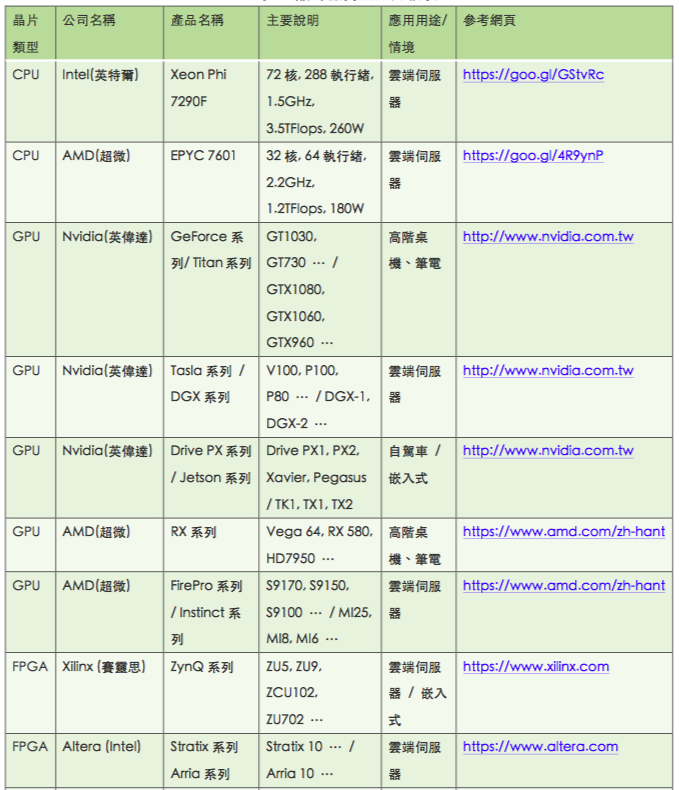
最後,將帶領各位Maker進入智能化的世界,你也能輕鬆成為一位AI應用創作者。
Maker如何進入AI領域?
對Maker而言,要如何進入智能化的世界呢?我們可從幾個方面來綜合評估:創作智能化目標、算力(AI晶片)、算法(模型/網路)、訓練資料及開發工具。
首先,確認創作內容的輸入和輸出項目為何?通常輸出與輸入的內容可能是數據(數值)、文字串、影像或語音。再來決定輸出的型式是分類(二分、多分類)還是迴歸(數值預測)問題(例如大小、位置、機率等)?或是更複雜的內容(例如一段影片、音樂、文章或連續動作產生)。
比方說想開發一台智能電扇,輸入的可能是一句話(命令、查詢)、一張影像(靜態手勢、表情等)、一段影片(動態手勢),或是溫濕度以及其它感測器。輸出的可能是一個動作(例如開關、調整電扇強度、轉動角度等)或是回答一句話(例如目前溫度、問候語句)。

再舉一個例子,假設要開發一個智能花盆,輸入的可能是土壤溫濕度、酸鹼度、照度感測器所提供的數值,或是一張彩色影像、熱像圖或是一句詢問的話。輸出的可能是自動語音提醒、開關澆水設備或是預測開花時間等。
選擇合適的硬體平台
確認創作主題的輸入和輸出項目後,再來是為功能驗證選擇合適的硬體平台。
決定計算的硬體平台是在雲端、本地端(邊緣)或者混合計算,來決定可容許計算結果的反應時間(微秒或秒級)、正確率、誤判率。當然最重要的是產品製作成本,以及後續服務的費用是否能被接受。
大家可能會想說,還沒做怎麼知道系統複雜度及成本?其實通常直接使用雲端AI服務時,開發與硬體成本會低一些,執行時反應速度也會因為連網問題而慢一些,然而後續使用的服務費用會高一些。
反之,若以本地(邊緣)端硬體解決AI計算時,則製作成本及開發難度會高一些,不過後續通常不需要額外使用雲端服務的費用。若是預計使用雲端服務(例如:Google, Microsoft, AWS等)時,通常供應商會提供很清楚的費用評估。
假如想在本地端解決計算問題,則可用類推法,先在網路上找看看是否有類似的設計(部份亦可),參考別人用了哪些硬體平台(AI晶片)、算法(模型),則可以省去很多評估的時間。
可直接使用智能晶片
另外,目前已有很多常用的智能(AI)功能已被晶片化(詳見本系列(中)篇),可考慮直接買來用。如果只想開發軟體不想碰硬體,也可考慮直接用高階智能手機或SoC解決方案,或是採用像樹莓派這類Maker最常用的開發平台,加上Movidius (Intel)或海青智盈(Gyrfalcon)USB神經棒這類的AI加速工具,也能玩出許多新創意。像是Nvidia TX1這類的小型嵌入式開發板已包含強大的CPU及GPU可以提供強大算力,是個不錯的選擇。

接著要考慮的是訓練資料的來源,以及是否需要進行前處理或清理(Data Clean),確保訓練過程不會失控而無法收歛。當然以深度學習來說,資料數量及樣態越多時,訓練效果將會越好,然而訓練時間也會呈現幾何成長,費用也會相當驚人。因此犧牲一點正確率,通常訓練的資料量就能減少一些。
若輸入的內容是感測器的量測值或者是聲音時,則可能要注意取樣速度及資料穩定性,必要時加上一些硬體或軟體的濾波器(Filter)來穩定資料。若資料點數不多、輸出反應速度要求不高的情況下,有時可直接用CPU計算即可滿足需求。若輸入的是影像,在人眼還可以辨別之下,可考慮改成灰階或小一點的尺寸,這樣可減少許多訓練的時間。
有很多問題運用統計、特徵提取比較或是傳統機器學習方法就可完成智能化需求,至於是否要用到深度學習這類計算成本很高的作法,就要依實際創作內容來評估。假設無法避免使用深度學習這類方法來處理時,此時選用的硬體平台除了要考慮計算能力外,還要考慮開發時所需使用的程式語言(Python, C, Java)、工具包(SDK)、深度學習框架的支援性。因為AI晶片目前沒有統一的開發介面,所以只能盡量挑選有支援像TensorFlow、 Caffe、Mxnet 這類較流行的框架。
如果是使用手機的SoC方案時,在Android 8.0以上還有Android NN API,或者像Arm Project Trillium這類的工具協助整合CPU、GPU、NPU,以便開發AI相關應用,而少數AI晶片可支援例如OpenVX、Cuda或OpenCL等GPU專用平行計算語言,也可以考慮使用。
結論
在這個AI晶片百家爭鳴的時代,不管是從雲端(Cloud)到邊緣(Edge)再到晶片(Chip),甚至連生態圈(Ecosystem)都已有完整的發展且快速成長中,同時網路上也有取之不盡的免費教學資源,所以正是Maker創作智能化的最佳時代。
俗話說:「沒有做不到只有想不到。」善用工具、發揮創意,相信不久的將來,每個人都會是最佳的AI應用創作者,就像在手機上開發程式一樣簡單。
各位Maker,就讓我們一起努力吧。

未來人人都可能是AI應用創作者
本文同步發表於MakerPro


沒有留言:
張貼留言