作者:Jack OmniXRI, 2023/7/3

相信大家最近幾個月都被大型語言模型(Large Language Model,LLM)及人工智慧生成內容(Artificial Intelligence Generated Content, AIGC)給驚豔(驚嚇)到了吧!?好像科幻電影「鋼鐵人」中的虛擬管家「賈維斯(Jarvis)」已經被實現出來了,如果家裡也能有一套,那該有多好啊。目前此類 AI 模型多半都非常巨大,通常只能透過雲端伺服器的強大算力才能運行。為了也能在單機上運行,開始有一些較小規模的模型搭配超強的CPU及GPU也能順利達到交談互動、文章生成等應用。
以往在AI模型部署優化及推論部份,通常都會想到使用 Intel OpenVINO,不過大家多半只注意到它在「電腦視覺」相關的應用,殊不知自從2022.1版後就已開始加入許多「自然語言」的範例。而最近2023.0版又更加強GPU(內顯HD Graphic, Iris,獨顯Arc)處理記憶體動態外形(Dynamic Shape)的能力,使得如生成型預訓練變換模型(Generative Pre-trained Transformer,GPT)這類基於轉換器(Transfomer)技術的大型語言模型能得到更好的實現。
此次很榮幸得到國內外知名工業電腦大廠「研華科技」提供最新的小型工業電腦主機 EPC-B2278 [1](Intel 12代CPU, i7-12700TE)進行測試,其中硬體部份還加入 Mobile PCI Express Module(MXM) 介面的 VEGA-X110 [2],即 Intel 最新獨立顯卡(Arc A370M) ,用來加速AI應用計算。而軟體部份則搭配 Intel OpenVINO 2023.0 來進行LLM模型優化及推論。
為了測試LLM的推論的效能,這裡使用了OpenVINO Notebooks範例中的 GPT-2 文字生成及開源 Dolly 2.0 對話生成進行測試。以下就依序從自然語言對話技術發展歷史、運行系統的硬體規格、軟體開發環境及LLM實驗結果來幫大家介紹一下。
1. 自然語言對話技術發展歷史
1950年電腦科學及人工智慧之父艾倫.圖靈提出了「圖靈測試」的想法,若人類透過打字或語音與遠方機器對話而無法分辨對方是否為機器就算通過測試,可以稱這部機器具有人類的「智慧」。經過許多電腦科學家多年努力,這項技術仍僅存在科幻電影中。直到2011年蘋果公司在iPhone上推出了「SIRI語音助理」,才讓大家對自然語言處理/理解(Natural Language Processing / Understanding,NLP/NLU)有了新的期待。
近十年來各種深度學習模型推陳出新,加上電腦計算速度、能處理的資料集大小及模型參數規模都有了大幅提升,使得NLP/NLU質與量上也隨之快速成長。2018年OpenAI提出一篇名為名為「Improving Language Understanding by Generative Pre-Training」的論文,提及「基於轉換器(Transfomer)的生成式預訓練模型」,從此奠定了GPT在LLM的重要地位。
2022年底OpenAI推出ChatGPT馬上引爆LLM及AIGC相關應用,其主要採用了互動交談來訓練及強化模型,即透過人類反饋的增強式學習(Reinforcement Learning from Human Feedback, RLHF),使得輸出更接近真人的自然語言處理、理解及學習特定領域知識。這項技術除了可以用來聊天、回答各式各樣的問題外,還可自動生成文章、快速摘要長文等功能。而今(2023)年便成為LLM及AIGC發展最迅猛的一年,僅不到半年就推出了數十個相關大型系統軟體,如GPT-4, Bard, LLaMA等,這對想投入AI應用服務的廠商有很大的幫助。
目前 LLM 有兩個較大的問題尚待解決,一是面對這些如此巨大的模型,通常還是得靠雲端大型、高算力設備(如GPU, TPU, NPU等)才能達到迅速回應的能力。二是向雲端發出問題來得到答案,有可能會泄漏個人隱私或公司機密。因此如何在本地端(不上網)使用中階設備就能提供這項服務,就變成大家努力的方向,這也是本文主要介紹的重點。
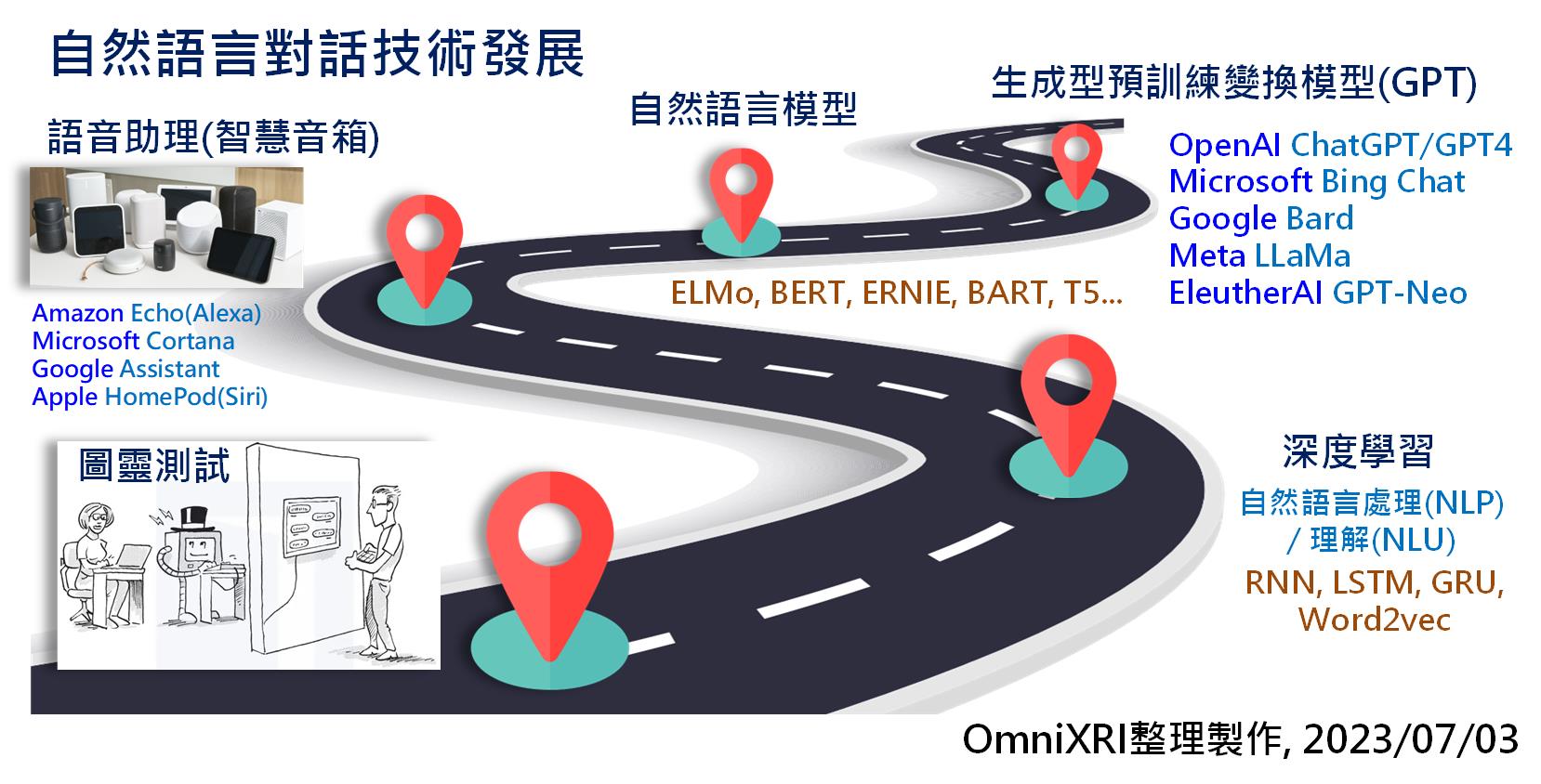
Fig. 1 自然語言對話技術發展示意圖。(OmniXRI整理製作, 2023/07/03)
2. 硬體規格簡介
此次由研華科技提供測試的主機短小精悍,體積不大,卻有超強算力,且功耗比起傳統搭載Nvidia高階顯卡的主機來得低上許多,所以主機內只需小型風扇就足以散熱,如Fig. 2所示。這台主機使用Intel 12代高效能CPU,內建有GPU HD Graphics 770(以下簡稱iGPU),另外加上一張MXM介面的Intel Arc370M的獨立顯卡(以下簡稱dGPU),可加強在AI推論上的效能。其完整規格如下所示。
主機:EPC-B2278 [1]
- CPU: i7-12700TE
- 64bit, 12 Cores, 20 Threads, 1.4G-4.6GHz
- iGPU, UHD Graphics 770, 32 EU, eDP 1.4b, DP 1.4a, HDMI 2.1
- Memory: DDR5, 4800MHz, 32GB
- Storge: SSD 256GB
- I/O: COM x2, USB x4, EtherNet x2, DP++ x2 (註:目前此款機器背板無HDMI接口,需自行使用DP轉換HDMI線材連接,其它同系列機種有不同擴充槽配置)
- 尺寸: 250 x 98 x 255 mm
- 重量: 5Kg
- 變壓器:24V / 9.58A, 230W
獨立顯卡:VEGA-X110 [2]
- Mobile PCI Express Module(MXM)
- Intel Arc A370M with 8 Xe-Cores (128EU)
- 1550MHz base clock
- GDDR6 4GB 64bit
- 8K DP1.4a x4

Fig. 2 研華科技EPC-B2278主機及VEGA-X110獨立顯卡示意圖。(OmniXRI整理製作, 2023/07/03)
3. 軟體開發環境安裝及測試
此次使用的主機出廠時並無安裝作業系統,初步測試可以安裝 Ubuntu 22.04 LTS (Linux) 及 Microsoft Windows 11。為了讓OpenVINO 2023.0版能更順利運行及對獨立顯卡AI加速計算的支援,所以選用了Win 11作為主要作業系統。
基於後續測試方便,這裡採用了 Intel OpenVINO 2023.0版提供的 Notebooks [3] 的範例,即 Jupyter Notebook (Python) 開發及測試環境。主要使用了以下兩組範例,更完整說明詳見第4及5小節。
- 223-text-prediction.ipynb [4]
- 240-dolly-2-instruction-following.ipynb [5]
使用前可參考[6]進行安裝 Python, Git 及 C++ Redistributable。接下來運行「cmd」進入命令列模式,執行下列命令創建Python虛擬環境。
python -m venv openvino_env
接著就可以執行下列命令啟動虛擬環境,啟動後命令例提示字元會變成(openvino_env)X:\Users\XXX,表示已進入虛擬環境。
openvino_env\Scripts\activate
若想離開虛擬環境,則可執行下列命令。
deactivate
如果你的系統上已有安裝其它版本的 OpenVINO ,則建議再新建一個虛擬環境以免相互干擾。
再來就可複製及安裝 OpenVINO Notebooks 及相關套件包,完成後就可以啟動 Jupyter Notebook 環境了。
openvino_env\Scripts\activate
git clone --depth=1 https://github.com/openvinotoolkit/openvino_notebooks.git
cd openvino_notebooks
python -m pip install --upgrade pip wheel setuptools
pip install -r requirements.txt
jupyter lab notebooks
啟動後會自動開啟網頁瀏覽器,並顯示所有的範例程式。此時命令列視窗會出現很多工作訊息,請勿關閉這個視窗。待需要結束工作時,關閉瀏覽器視窗後再關閉此命令列視窗,或按 Ctrl+C 回到命令列提示字元。下次再次啟動命令列視窗時,只需執行下列命令就能進入 Jupyter Notebook 工作環境了。
openvino_env/Scripts/activate
cd openvino_notebooks
jupyter lab notebooks
4. 大型語言模型GPT-2文字預測及生成結果
Intel OpenVINO Notebooks 在2022.1版時就有開始提供 GPT-2的文字生成範例 「223-gpt2-text-prediction」,2022.3版又將這個範例擴展,加入GPT-Neo文字生成及PersonaGPT對話生成,變成 「223-text-prediction」。此次實驗用的是2023.0版「223-text-prediction」[4],這個範例和2022.3版略有些許不同。同時2023.0版也開始提供 Google Colab範例[7],讓不想在自己電腦安裝OpenVINO的朋友可以嚐試一下這個LLM的應用。
以下實驗會使用第3節介紹的方式在本地端(不上網單機)上運行範例,方便計算相關實驗數據。使用時很簡單,如Fig. 3所示,選定欲執行的範例檔案夾,進入後以滑鼠雙擊想執行的檔案(*.ipynb)即可載入,接著點擊主選單上的「Kernel」下的「Restart Kernel and Run All Cells…」,就可一口氣跑完範例程式。
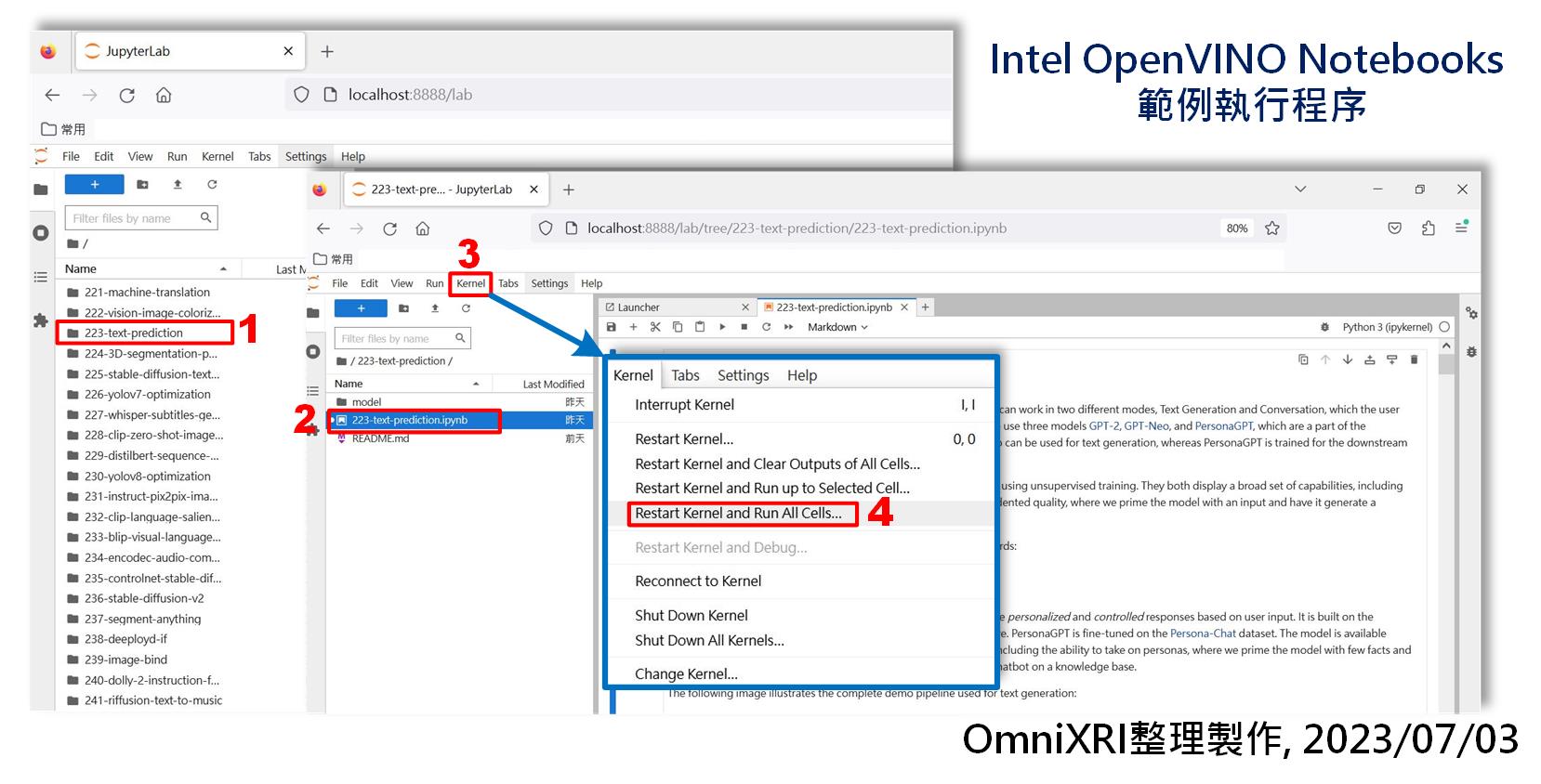
Fig. 3 Intel OpenVINO Notebooks範例執行程序示意圖。(OmniXRI整理製作,2023/07/03)
在這個範例中,都是使用HuggingFace Transformers預訓練好的模型,目前只支援英文,共有下列三種。
- GPT-2
- GPT-Neo
- PersonaGPT
前兩項主要為文章生成(或稱文字預測),第三項主要用於對答(聊天)。接下就分別說明個別的測試結果。
4.1 PersonaGPT測試結果
如果直接選擇運行全部,預設會選擇第三項 PersonaGPT,運行前會先將HuggingFace的模型先轉成ONNX格式,接著再轉換成OpenVINO IR格式(*.xml + *.bin)來進行推論。運行前還可依需求選擇不同的硬體(如CPU, iGPU, dGPU)以得到不同的效能。這個範例最後一個步驟預設了四個問題,重覆發問,共問十次。實驗後會發現每次執行最後一個步驟問同樣的問題,確實會產生不同的答案,如Fig. 4所示。如果想要測試一下自己的問題,可以把最後一格的程式中的 pre_written_prompts 變數內容修改一下即可。不過仔細看了一下答案,有時答的還可以,但有時也會答非所問,或許未來這個模型還會再加強吧!
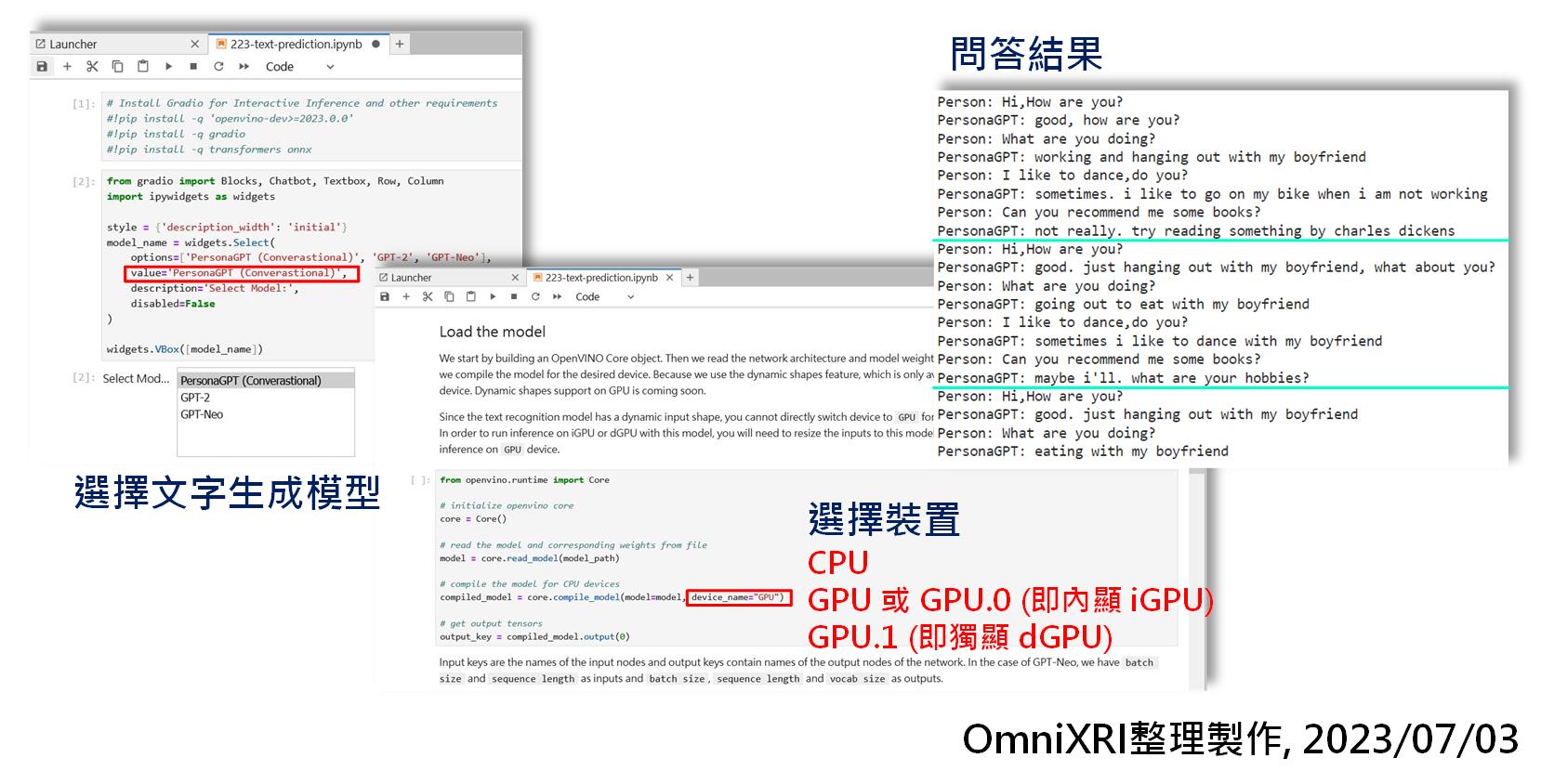
Fig. 4 PersonaGPT生成設定及問答結果。(OmniXRI整理製作,2023/07/03)
為了比較不同的硬體下運行PersonaGPT的效率,使用了研華提供的硬體和筆者筆電進行運行比較,結果詳如Fig. 5。其中「Total」表示全部運行完所需時間,而「Inference」則只運行最後一個步驟的十次問答。結果出來,乍一看研華的iGPU和dGPU怎麼比CPU跑得還慢,但仔細確認後發覺使用CPU運行最後一個步驟時,所有算力幾乎被吃光佔了93%,而單獨使用iGPU時只用到57%,而只使用dGPU才用到19%,猜想OpenVINO在配置計算資源可能沒有用到最大值,可能還有改善空間,或者還有隱藏版的設定,有待大家一起來研究。

Fig. 5 不同硬體運行PersonaGPT生成效能比較表。(OmniXRI整理製作,2023/07/03)
另外也有使用Google Colab來跑一下這個範例,結果竟然得到Total 491.2ms, Inference 116.4ms的超長推論時間結果,猜想可能是只能使用到 Intel Xeon CPU 單核心運行導致吧?
4.2 GPT-2 & GPT-Neo測試結果
目前這個範例若想使用 GPT-2 或 GPT-Neo 來生成一小段文章時,首先修改「value=‘GPT-2’」或「value=‘GPT-Neo’」,接著選擇想要推論的裝置(CPU, GPU, GPU.1)。再來點擊「Inference with GPT-Neo/GPT-2」那格程式,修改「text = ‘欲產生文章的一小段提示文字(目前只支援英文)’」。最後點擊主選單「Kernel」下的「Restart Kernel and Run up to Selected Cell…」使其程式重啟運行至目前格子,即可產生一段文章。如果不滿意,可以單獨運行這格就能得到新產生的內容。完整結果可參考Fig. 6所示。

Fig. 6 GPT-2或GPT-Neo文章生成結果示意圖。(OmniXRI整理製作,2023/07/03)
5. 大型語言模型Dolly 2.0離線對話測試結果
目前LLM雖有不少開源項目,但OpenVINO目前官方僅提供了Dolly 2.0的範例,這是一個開源的項目,由Databricks提供,其主要訓練資料集是由自家的員工建立的15,000條高品質問答產生的,所以大家可以放心使用,不管是否從事商業用途,更完整的介紹可參考官方的說明[8]。
由於這個模型所需使用到的記憶體比較多,且只支援OpenVINO 2023.0版及較新的CPU, iGPU, dGPU,所以在筆者的筆電(Core i7-9750H)上就無法順利運行。
想要運行這個範例,非常簡單,只需開啟 Notebooks 240-dolly-2-instruction-following 路徑下的 240-dolly-2-instruction-following.ipynb,再點選主選單上的「Kernel」下的「Restart Kernel and Run All Cells」,就可順利運行起來。
這個範例有使用gradio套件,它是用來在Jupyter Notebook Python環境下產生圖形化使用者介面(GUI)的工具,所以當執行到最後一步驟時,除了Jupyter Notebook上會產生GUI外,另外可使用網頁瀏覽器連線到「127.0.0.1:7860」,亦會得到一樣的操作畫面,如Fig. 7所示。
操作時只需在「User Instruction」欄位輸入待回答的問題,或者直接從下方「Examples」選擇一個測試用問題,再點選「Submit」提交推論計算,稍待一會兒,「Model response」區就會慢慢逐字產生合理答案。同樣地,相同的問題每次發問後會得到不一樣的結果。在產生答案的同時,系統也會計算產生的速度(單位為 Tokens/Second),CPU大約可得到4.0到4.4,而iGPU則只能得到3.2到3.8左右,而dGPU有些時候會產生運行錯誤導致程式需要重新啟動運行。另外在切換裝置時,由於 OpenVINO 需重新編譯對應的格式,所以可能需等待1到3分鐘後才能再發問。
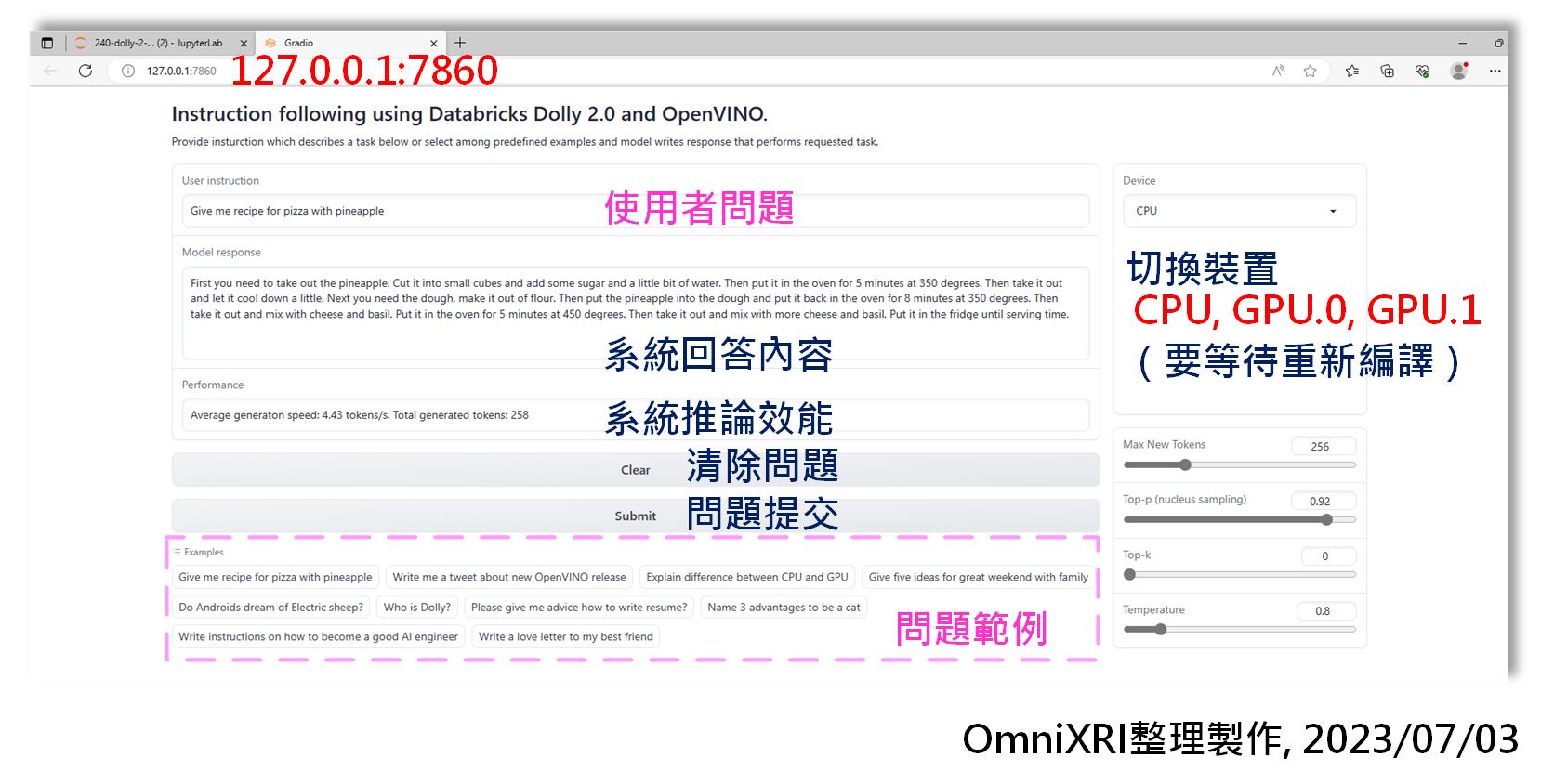
Fig. 7 OpenVINO運行Dolly 2.0範例後網頁使用者介面示意圖。(OmniXRI整理製作,2023/07/03)
初步觀察後這個範例亦有發現iGPU的效能略優於dGPU的狀況,猜想可能獨立顯卡的重點都放在3D顯示效能的優化,而對於OpenVINO的AI加速計算上支援還有些不足。另外目前iGPU和CPU共享記憶體,32GB遠大於dGPU的4GB,所以也有可能造成效能差異,或許不久的將來就能得到改善。
小結
初步體驗後,徹底改變了傳統的刻板印象,原來不是只有雲端大機器才能跑得的動LLM及AIGC,在中小型工業電腦上一樣可以達到滿意的推論水準。目前 OpenVINO 在 CPU 及 iGPU 上推論的表現已有不錯的整合,相信未來在 dGPU 更強大的算力加持及 OpenVINO持續優化下會有更棒的表現,那麼更複雜、多工的邊緣智能應用就更容易實現了。
參考文獻
[1] 研華科技,嵌入式電腦,EPC-B2278 (Intel® 12th Gen Core™ i processor)
https://www.advantech.com/zh-tw/products/f3245050-a6a2-4a97-a6b1-551f82f72305/epc-b2278/mod_87e56b88-4062-4256-ad2d-8c015f21adf7
[2] 研華科技,邊緣智能解決方案,VEGA-X110 (Intel Arc A370M Embedded GPU)
https://www.advantech.com/zh-tw/products/3d060f1e-e73e-460d-b38c-c69f76312c91/vega-x110/mod_678bd5c3-d349-47fc-92f4-033d8e9a00cb
[3] Intel openvinotoolkit github - openvino_notebooks
https://github.com/openvinotoolkit/openvino_notebooks
[4] Intel openvinotoolkit github - openvino_notebooks/notebooks/223-text-prediction
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/223-text-prediction
[5] Intel openvinotoolkit github - openvino_notebooks/notebooks/240-dolly-2-instruction-following
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/240-dolly-2-instruction-following
[6] Intel openvinotoolkit github - openvino_notebooks windows install
https://github.com/openvinotoolkit/openvino_notebooks/wiki/Windows
[7] Intel openvinotoolkit github - 223-text-prediction Google Colab Example
https://colab.research.google.com/github/openvinotoolkit/openvino_notebooks/blob/main/notebooks/223-text-prediction/223-text-prediction.ipynb
[8] Databricks, Free Dolly: Introducing the World’s First Truly Open Instruction-Tuned LLM
https://www.databricks.com/blog/2023/04/12/dolly-first-open-commercially-viable-instruction-tuned-llm
延伸閱讀
[A] 許哲豪,Intel OpenVINO 2023.0初體驗─如何快速在Google Colab運行人臉偵測
https://omnixri.blogspot.com/2023/06/vmaker-edge-ai-06-intel-openvino.html
[B] 楊亦誠,利用OpenVINO部署HuggingFace預訓練模型的方法與技巧
https://makerpro.cc/2023/06/how-to-use-openvino-deploy-pre-trained-model-huggingface/
本文同步發表在【MakerPRO】


沒有留言:
張貼留言