
之前曾寫過「使用Google Colaboratory免費資源學AI,正是時候! [A]」、「如何以YOLOv3訓練自己的資料集─以小蕃茄為例 [B]」獲得許多點閱及迴響,但隨著AI工具及版本不斷演進,導致這些範例已有部份無法順利運作。為了讓新手入坑能快速體驗自定義資料集的「物件偵測」智能應用,且不用頭疼開發環境建置及硬體算力,於是重新寫了這篇文章分享給大家。
在這個範例中將採用雲端、免費的Google Colab CPU+GPU運算資源及內建的Jupyter Notebook加上Python開發環境,搭配最常見的Darknet及Yolov4-tiny物件偵測框架,來完成自定義物件的模型訓練及物件偵測的推論。本文將著重在實作,而略過算法的原理說明,有興趣深入了解的朋友請自行參閱[1]。接下來就從【資料集建置與標註】、【Darknet安裝與Yolov4-tiny測試】、【自定義資料集訓練】、【訓練及推論實驗結果】依序為大家作進一步說明,完整範例程式請參考下方連結。
https://github.com/OmniXRI/Yolov4-tiny_Colab_User_Datasets
*資料集建置與標註
一般來說,公開資料集很容易取得,且主要幾個知名的資料集(如VOC, ImageNet, COCO [2])通常也都被當成公開模型的預訓練資料集,像此次要介紹的Yolo v3 / v4系列就是以COCO [2](80類別)作為預訓練資料集。除了上述內容外,如需其它資料集亦可參考[3]。所以如果剛好需要的物件偵測應用落在這些資料集類別中,那就不用自己建置直接使用即可,因為自己很難收集和標註這麼大規模的資料集。當然,如果嫌指定的類別資料集數量不足或者需求不同,亦可加上自定義的內容重新訓練。
除了現有公開資料集外,大家亦可自行建立自定義的資料集,收集方式可為自行拍照、攝影(從連續視訊中抽取部份影像)或者從網路上收集無版權的影像內容。在這個範例中,單純為了方便大家測試,在網路上隨機收集了100張具有狗臉、貓臉和人臉等三種物件的影像,並盡可能使其分佈平均,包括同一張影像中有1~3種物件,1~6個物件,物件有大有小(佔影像長寬比例),相同物件類別(例如狗臉)亦有不同姿態(如頭部旋轉、偏擺、俯仰等)、型態(花色、品種、拍攝角度等)及背景(純色、複雜實景等)。不過請注意,這個資料集影像僅供本範例實驗用,相關版權為原始作者所有,請勿移作它用。因此大家只需仿效這個作法,依自己想建立的類別數量進行收集足夠數量及多樣性的原始資料集即可。
 |
| Fig. 1 狗臉、貓臉及人臉三物件自定義資料集示意圖。(點擊圖放大) |
有了資料集,接下來就要開始進行標註。網路上有很多免費開源的標註工具[4],這裡使用最常見且最簡單的LabelImg[5]。這項工具對於物件偵測方面可提供VOC(*.xml)及YOLO(*.txt)的標註格式,這個範例直接選用YOLO格式輸出,省去轉檔動作。如果資料集來自其它格式(如VOC)請自行尋找轉檔工具程式。另外標註操作方式網路上有很多介紹文章,可直接參考[5]或者「建立自己的YOLO辨識模型 – 以柑橘辨識為例 [6]」這裡就不多作說明。
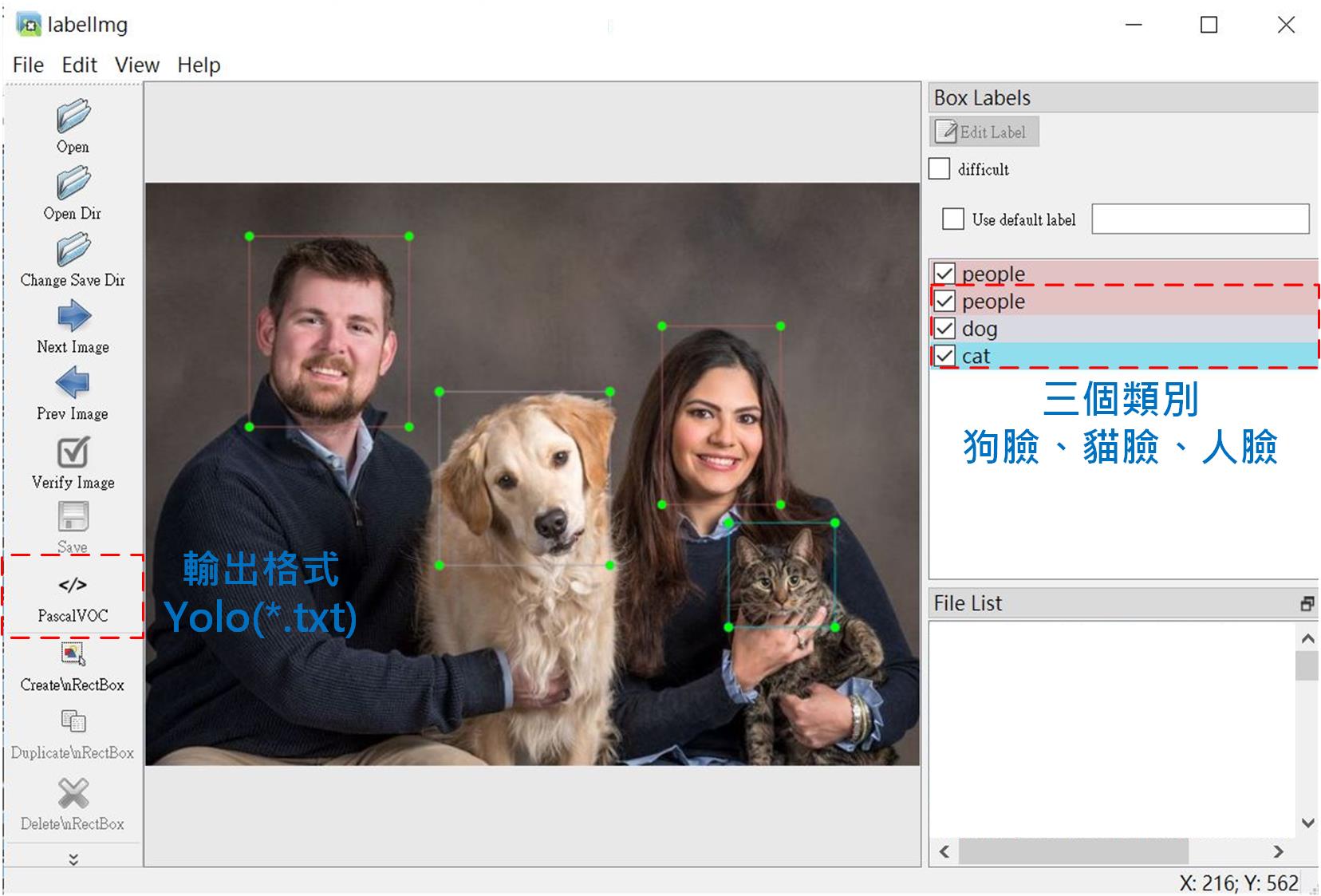 |
| Fig. 2 LabelImg標註工具操作畫面。(點擊圖放大) |
*Darknet安裝與Yolov4-tiny測試
本範例主要包含下列內容,接下來就針對主程式內容逐一說明。
- yolov4-tiny_training_test.ipynb 為主程式,包含Yolov4-tiny預訓練測試、自定義資料集訓練及推論測試
- my_dataset.zip 包含100張影像及Yolo格式標註檔(*.txt)
- my_obj.data 為資料集設定檔
- my_obj.names 為資料集分類標籤名稱
- my_yolov4-tiny-custom.cfg 為自定義模型及相關參數
- my_train.txt 為自定義資料訓練集檔案名稱列表
- my_val.txt 為自定義資料驗證集檔案名稱列表
- test01.jpg, test02.jpg 為測試用影像
1. 驗證Nvidia GPU及CUDA版本
確認運行環境(本步驟可略過),由於GPU每次配置可能不同,可能為 K80, T4, P100,記憶體大小可能會影響到後續訓練時Patch Size大小。若想要好一點的GPU則重覆斷開連線(Ctrl+M)再重新連線,直到出現期望的GPU出現,再進行下一個步驟。
!nvidia-smi !/usr/local/cuda/bin/nvcc --version
2. 連接Google Drvie雲端硬碟
請先在自己的Google Drive上建立一個yolov4-tiny的空檔案夾,方便後續訓練時可暫存權重檔到此處。 掛載Google Drvie(雲端硬碟),點擊網址(Go to this URL in a browser),允許連結,再複製授權碼貼到空格(Enter your authorization code)中。 建立捷徑 /my_drive 指向已掛載之Google Drvie (/content/drive/MyDrive/)
from google.colab import drive
drive.mount('/content/drive')
!ln -s /content/drive/MyDrive/ /my_drive
!ls
!ls /my_drive
3. 下載darknet及Yolov4-tiny預訓練權重檔
這裡主要使用YOLO系列的原始框架Darknet而非其它TensorFlow, PyTorch,ONNX格式,而為了能順利快速展示整個工作流程,所以選用Yolov4-tiny而非Yolov4。如果想替換成其它系列可參考官網[1]說明。
# 下載darknet !git clone https://github.com/AlexeyAB/darknet # 下載yolov4-tiny預訓練權重檔(23.1MB),僅供測試darknet用,後續自定義訓練用不到。 !wget -N https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights !ls
4. 修改Makefile參數
將GPU, CUDNN, CUDNN_HALF, OPENCV設為可用
- GPU=0 --> GPU=1
- CUDNN=0 --> CUDNN=1
- CUDNN_HALF=0 --> CUDNN_HALF=1
- OPENCV=0 --> OPENCV=1
%cd darknet !sed -i 's/OPENCV=0/OPENCV=1/' Makefile !sed -i 's/GPU=0/GPU=1/' Makefile !sed -i 's/CUDNN=0/CUDNN=1/' Makefile !sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile
5. 編譯darknet
!make
6. 測試darknet編譯結果
- 檢查目前工作路徑是否在 darknet 路徑。
- 執行darknet物件偵測推論,指定 data, config, weight, image 所在位置(darknet/data/ 路徑下有幾張jpg影像可供測試)。
- 顯示結果影像predictions.jpg。
!ls
!./darknet detector test cfg/coco.data cfg/yolov4-tiny.cfg ../yolov4-tiny.weights data/dog.jpg
import cv2 # 導入OpenCV函式庫
from google.colab.patches import cv2_imshow # 導入Colab.patches函式庫
imgResult = cv2.imread('predictions.jpg') # 讀入結果影像
cv2_imshow(imgResult) # 顯示結果影像
 |
| Fig.3 Darknet (Yolov4-tiny)推論測試結果。(點擊圖放大) |
*自定義資料集訓練
接下來就可以開始訓練自己準備好的資料集,但在開始之前我們還要準備幾個檔案。
7. 準備自定義預訓練權重檔、資料集及相關參數檔
從 https://github.com/AlexeyAB/Darknet#how-to-train-tiny-yolo-to-detect-your-custom-objects 下載自定義預訓練權重檔 yolov4.conv.29。如果想換成Yolov4或其它系列模型進行訓練,則請參考官網[1]說明下載對應的預訓練檔及修改config檔案。
從Github中下載自定義資料集和相關參數檔(這個範例已幫大家準備了一份)
資料集(my_dataset.zip)中共有100張影像(*.jpg,內容為狗臉、貓臉及人臉三種物件)及yolo格式(*.txt)標註檔。
參數檔包含下列內容,可依資料集實際內容進行修改。
- my_obj.data (物件資料設定,含物件類別、訓練驗證路徑、備份權重路徑)
- my_obj.names (物件類別名稱,每一列為一個類別名稱)
- my_yolov4-tiny-custom.cfg (設定模型組態)
- my_train.txt (訓練內容檔案名稱,取資料集前80組,可自行定義)
- my_valid.txt (驗證內容檔案名稱,取資料集後20組,可自行定義)
其中第3項my_yolov4-tiny-custom.cfg是從/darknet/cfg/yolov4-tiny-custom.cfg須修改而得,修改內容如下,須依自定義資料集內容而定。
line 6 : batch=64 # 可依顯卡記憶體調整
line 7 : subdivisions=1 # 可依顯卡記憶體調整
line 8 : width=416 # 須為32的倍數
line 9 : height=416 # 須為32的倍數
line 20 : max_batches=6000 # 類別數量(classes)x2000,目前類別數量為3
line 22 : steps=4800,5400 # 為max_batch值的 80%, 90%
line 212, 263 : filter=24 # 為(classes+5)x3
line 220, 269 : classes=3 # 物件類別數量
最後將相關參數檔複製到/darknet對應路徑下。
#回到使用者根目錄 %cd /content # 下載yolov4-tiny自定義權重檔yolov4-tiny.conv.29(18.8MB) !wget -N https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29 # 下載資料集和相關參數檔 !git clone https://github.com/OmniXRI/Yolov4-tiny_Colab_User_Datasets !ls # 相關參數到對應路徑下 !cp Yolov4-tiny_Colab_User_Datasets/my_yolov4-tiny-custom.cfg darknet/cfg !ls darknet/cfg !cp Yolov4-tiny_Colab_User_Datasets/my_obj.names darknet/data !cp Yolov4-tiny_Colab_User_Datasets/my_obj.data darknet/data !cp Yolov4-tiny_Colab_User_Datasets/my_train.txt darknet/data !cp Yolov4-tiny_Colab_User_Datasets/my_val.txt darknet/data !ls darknet/data # 將資料集解壓縮到指定路徑 !unzip Yolov4-tiny_Colab_User_Datasets/my_dataset.zip -d darknet/data !ls darknet/data/my_dataset/
8. 開始訓練
由於整個訓練過程會依分配到的GPU等級及網路通訊速度,約要一到一個半小時。正常情況可使用8.1的程序直到完成訓練。但若遇到半途被不明原因中斷,則需以8.2的程序重新接續訓練。
8.1 正常重新訓練
指定.data, .cfg, 預訓練參數檔並開始訓練,如需記錄平均精確度mAP(mean average precisions)可加上參數 -map。如果訓練過程很容易無故中止則建議移除參數 -map。
訓練期間會記錄Loss並繪成圖表(darknet/chart_my_yolov4-tiny-custom.png),可隨時重新開啟觀察訓練成果。
每隔1000次會自動備份一次權重檔到雲端硬碟/my_drive/yolov4-tiny下(根據my_obj.data中backup設定值),檔名為my_yolov4-tiny_x000.weights (x為1~n)。
訓練期間會自動產生my_yolov4-tiny_best.weights和my_yolov4-tiny_last.weights,完成訓練會產生my_yolov4-tiny_final.weights。
這裡要注意雲端硬體要有足夠空間存放,否則空間不足時就無法備份權重值。
%cd /content/darknet !./darknet detector train data/my_obj.data cfg/my_yolov4-tiny-custom.cfg ../yolov4-tiny.conv.29 -map -dont_show
 |
| Fig. 4 訓練過程損失(Loss)及類別平均精確度(mAP)變化圖(chart_my_yolov4-tiny-custom.png)。(點擊圖放大) |
8.2 重新接續執行訓練
前一步驟有設定備份訓練過程的權重檔,若遇到執行到一半就斷線,此時可以從Google Drive中把最後一次權重檔 my_yolov4-tiny-custom_last.weights 複製到Colab darknet/backup下,再重新啟動訓練。
!cp /my_drive/yolov4-tiny/my_yolov4-tiny-custom_last.weights backup/ !ls backup/
*訓練及推論實驗結果
- 完成訓練後,可將結果權重檔my_yolov4-tiny-custom_final.weights複製到Colab虛擬機中。
- 執行darknet物件偵測推論,指定 data, config, weight, image 所在位置,/Yolov4-tiny_Colab_User_Datasets下有test01.jpg和test02.jpg可供測試。
- 顯示結果影像predictions.jpg
!cp /my_drive/yolov4-tiny/my_yolov4-tiny-custom_final.weights ../
!ls
!./darknet detector test data/my_obj.data cfg/my_yolov4-tiny-custom.cfg ../my_yolov4-tiny-custom_final.weights ../Yolov4-tiny_Colab_User_Datasets/test01.jpg
import cv2 # 導入OpenCV函式庫
from google.colab.patches import cv2_imshow # 導入Colab.patches函式庫
imgResult = cv2.imread('predictions.jpg') # 讀入結果影像
cv2_imshow(imgResult) # 顯示結果影像
 |
| Fig.5 Test01.jpg測試結果。(點擊圖放大) |
 |
| Fig.6 Test02.jpg測試結果。(點擊圖放大) |
*小結
透過以上的範例,大致上就能讓大家做一些簡單的「物件偵測」實驗,如果想更進一步擴大實驗,可增加物件的類別、資料集的大小、模型的種類(如Yolov4等)來完成自定義資料集的訓練及推論。此次範例的運行如此順利(Loss快速收歛,未發散或振盪)可能是因為安排的三個類別和Yolo預訓練資料集COCO中的某些類別很類似的緣故,因此當換成其它自定義資料集可能就不見得會如此順利。
另外這裡提醒大家一點,Google Colab雖然很方便,但GPU的資源也不是無限制可以一直使用,除了基本的12小時(通常幾個小時就可能斷掉)限制外,如果經常(多次數)長時間使用GPU在訓練,有時也會暫時被暫停使用GPU一到數天的使用權限。所以如果真的需要長時間使用的朋友,建議還是得買張獨立顯卡來跑。
參考文獻
[1] Yolo v4, v3 and v2 for Windows and Linux
https://github.com/AlexeyAB/darknet
[2] Microsoft Common Objects in Context
https://cocodataset.org
[3] Papers with code - Datasets
https://paperswithcode.com/datasets
[4] Jack Hsu, 【AI HUB專欄】如何建立精準標註的電腦視覺資料集
http://omnixri.blogspot.com/2020/10/ai-hub_16.html
[5] tzutalin, Github - labelImg
https://github.com/tzutalin/labelImg
[6] CH.Tseng, 建立自己的YOLO辨識模型 – 以柑橘辨識為例
https://chtseng.wordpress.com/2018/09/01/%E5%BB%BA%E7%AB%8B%E8%87%AA%E5%B7%B1%E7%9A%84yolo%E8%BE%A8%E8%AD%98%E6%A8%A1%E5%9E%8B-%E4%BB%A5%E6%9F%91%E6%A9%98%E8%BE%A8%E8%AD%98%E7%82%BA%E4%BE%8B/
延伸閱讀
[A] Jack Hsu, 【Maker玩AI】使用Google Colaboratory免費資源學AI,正是時候!
http://omnixri.blogspot.com/2018/06/makeraigoogle-colaboratoryai.html
[B] Jack Hsu, 【AI_Column】如何以YOLOv3訓練自己的資料集─以小蕃茄為例
http://omnixri.blogspot.com/2019/11/aicolumnyolov3.html
[C] Jack Hsu, 【課程簡報】20201024_AIGO LAB解題實務工作坊(二)_採果辨識解題與技術開發
http://omnixri.blogspot.com/2020/10/20201024aigo-lab.html


沒有留言:
張貼留言