作者:Jack OmniXRI, 2023/10/16
相信有開發過邊緣智慧應用的朋友,一定都會經歷資料收集標註、模型選用訓練調參及部署推論檢驗的步驟。當模型訓練完成後,在測試集表現還不錯,但到了真實場景卻一塌糊塗,推論準確度急速下降。此時就要重新檢視資料集各分類是否有足夠數量的樣本及多樣性,即可以包含更大範圍的應用場景內容。
為解決這項問題,通常可以重新取樣、增加樣本數量和多樣性來解決,但不幸地是有時無法重新取樣,或部份分類的樣本不易取得。此時就要靠資料擴增(Data Augmentation)手法來協助擴展資料集的數量和多樣性,以利模型在訓練時能學習到對應的特徵,確保訓練結果在部署後也能保持一定的推論精度。
以下就簡單盤點一些常見的資料擴增手法,包含影像類(二維資料)及時序類(一維資料,如聲音、溫度、振動等各式感測器產生的連續信號),希望能帶給大家一些幫助。
1. 影像資料擴增
常見影像類AI應用場景,包括影像分類、物件偵測、影像分割、姿態估測等。這些應用常會因拍攝角度(俯仰角)、視角(焦距長度)、距離(遠中近)、光照(角度、色彩、強弱等)、解析度(含傳輸破壞性壓縮造成的變化)、運動模糊等問題,造成同一物體會產生各式各樣的影像樣本。如果再加上物體本身的變形,如人臉表情、人體姿態、外表色彩(如化妝、衣服配件、動物毛色等)、部份重疊遮蔽等各式各樣的干擾,那樣本的多樣(變化)性就更高了,所以才需要使用資料擴增技術來消除一部份資料集數量及多樣性不足的問題。[1]
以下簡單列出常見「影像處理式」、「影像拼貼式」及「影像生成式」三大資料擴增方式。
1.1. 影像處理式
在「影像分類」應用中,單張影像通常只會有一個主體物件和一個標籤。對於被訓練的模型來說,輸入影像只要有一些差異,在訓練時就能微調到部份權重值。因此透過傳統影像處理軟體,如Photo Shop, OpenCV等,就能利用影像處理函式快速產生些微差異的影像。當同一張影像有多個分身時,就能讓模型訓練後的容錯率增加,進而學習到更有效的特徵。常見手法如下清單,如Fig. 1所示。
- 位置調整: 平移、旋轉、左右鏡射、上下翻轉
- 影像變形: 縮放、仿射(傾斜)、透視(投影)
- 亮度/色彩調整: 亮度、對比(伽傌、等化)、色調、飽和(彩度)、自由色階(亮度、紅/綠/藍通道)
- 解析度調整: 銳化、模糊、雜訊
當然以上手法可單獨處理,亦可多項組合一起處理,處理時還可加入指定的隨機值,這樣就能產生更多變化的內容了,讓一張影像可以擴增到指定的數量。

Fig.1 常見影像處理式資料擴增手法。(OmniXRI整理製作, 2023/10/16)
1.2. 影像拼貼式
在「物件偵測」應用中,一張影像中有許多物件,每個物件會依大小標註好物件框(Bounding Box),若想要有更多資料集,可採用破壞或拼貼方式來增加,常見手法如下清單,如Fig. 2所示。
- 影片挖洞/填色(填料): 在影像上隨機位置及大小進行挖空(填入黑色)、填色(填入指定顏色)、填料(填入指定材質)。以破壞部份內容來增強物件部份遮蔽的檢出能力。
- 馬賽克: 將多張影像拼貼在同一張影像,可以是等分或隨機拼貼,相當於對影像進行平移加縮放處理,如此即可增強對不同尺寸及位置的物件偵測能力。新的拼貼影像產生時除了要合併原有物件框類別數量外,還要調整其對應大小、位置,產生新的標註檔案。

Fig. 2 常見影像拼貼式資料擴增手法。(OmniXRI整理製作, 2023/10/16)
1.3. 影像生成式
對於不容易收集樣本或樣本數量極不平衡的應用,或者要快速得到精準「影像分割(像素級分類)」標註資料時,此時就可考慮使用「無中生有」影像生成的方式來產生樣本。不過這種手法施行上有很多限制,且常需要預訓練另一個超大的模型,因此不一定適合所有應用。常見手法如下清單,如Fig. 3所示。
生成對抗網路(GAN): GAN主要有兩個動作用來訓練模型,一個負責生成虛假內容,一個負責辨識是否為虛假內容,若無法正確辨識出真假就調整模型參數直到能成功辨識,經過多張樣本訓練後,即可得到優秀的生成及辨識模型。接著就可利用這項特性,生成不存在但又極為真實的影像。不過訓練時還是要給予適當數量及多樣性(含不同背景)的樣本,如此才能生成所需的樣本。例如給予男女老少或喜怒哀樂的人臉樣本進行訓練,這樣就能生成各種人物的表情,但資料集中並沒有動物的影像,所以不管怎麼訓練也是無法生成豬或狗臉。另外由於需要大量時間才能完成,所以實務上採用是否符合成本,會依個案而有不同。
立體渲染 / 數位孿生(3D Rendering / Digital Twins): 一般要將真實世界的影像進行像素等級分割標註時,很難得到精細結果,若要精細分割則一張影像可能要數分鐘到數十分鐘才能完成,非常不利於建立資料集。例如自駕車所需的街景影像,可能包含光照、天候、視角、移動物體等,每秒又需取得數張到數十張移動造成些許差異的影像,此時若使用人工方式進行影像分割標註,會變得極為困難。因此如果使用3D建模方式,建立極為接近真實環境的場景、移動物件(如人、車)並給予適當的材質、打光進行渲染,就像電玩實境賽車,這樣便能快速、輕易地得到精細的分割影像標註資料。同樣地,在工業視覺檢測中,也常有3D物件資料不易建立資料集問題,此時以空的背影加上3D物件的各個面向(距離、視角、材質、光照等)進行合成,這樣也能快速建立大量的資料集,提供訓練模型使用。
人工智慧生成(AIGC): 近來AIGC工具成熟,如Midjourney, OpenAI Dall-E2, Stable Diffusion等,已預訓練了超巨大模型(數千億到數兆個參數),只要輸入文字描述就能自動產生一個非常擬真的影像,且每次都會有些許差異,這樣很方便就能產生多樣態的資料集。不過目前生成的效率仍不好,從數秒到數百秒不等,有待未來電腦計算速度的提升。

Fig. 3 常見影像生成式資料擴增手法。(OmniXRI整理製作, 2023/10/16)[2] [3]
2. 時序資料擴增
時序資料通常就是透過感測器以固定時間或頻率取樣而得,常見的感測器如麥克風(語音、環境音等)、溫度、濕度、振動(加速度計、陀螺儀、地磁計)、光照、重量、轉速等,大多都是轉換成電壓信號,再經類比數位轉換器(ADC)將其轉換成數位資料以方便後續分析計算用,如分類、預測等[4]。由於真實世界會有很多雜訊干擾,所以取得的資料進行模型訓練後,容錯性會較差,因此可以透過以下手法進行擴增,有效提升模型的適用性。常見手法如下清單,如Fig. 3所示。
- 抖動(Jittering)
- 縮放(Scaling)
- 振幅扭曲(Magnitude Warping)
- 信號反轉(Rotation)
- 排列置換(Permutation0
- 視窗切片(Window Slice)
- 時間扭曲(Time Warping)
- 視窗扭曲(Window Warping)
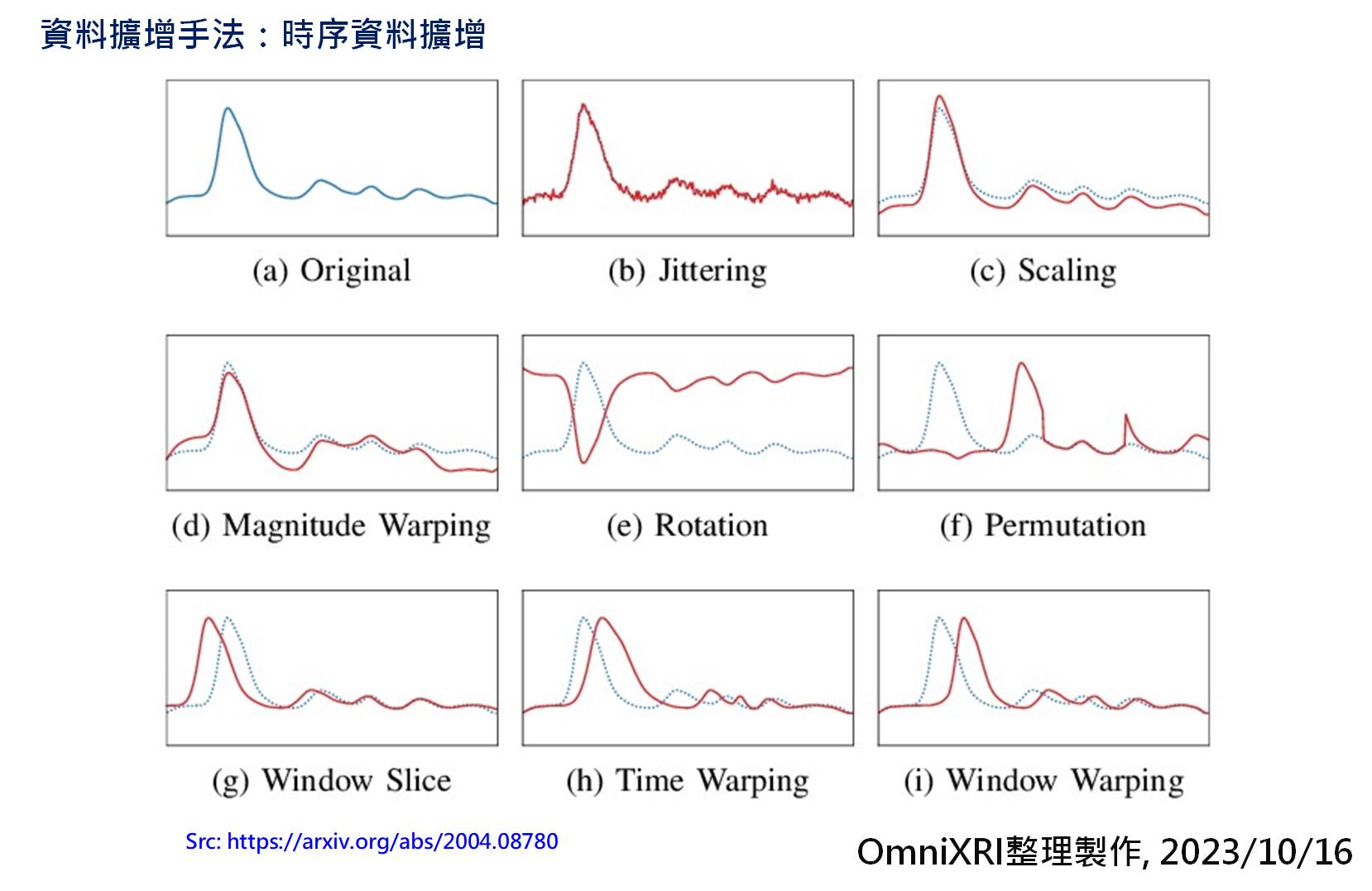
Fig. 4 常見時序資料擴增手法。(OmniXRI整理製作, 2023/10/16)[1]
小結
以上簡單的介紹了多種資料擴增手法,雖然這些方式可以暫時、快速地解決資料不足及難以取得的問題,但根本解決之道還是要多花點時間採集真實世界產生的內容並仔細標註,增加樣本的多樣性,如此才能讓模型在訓練時學到更多的特徵,確保部署後能得到更接近的推論精度。就像學生多作不同出版社的題庫,適應各種題型和出題方式,這樣在大考時就能得到和練習時一樣優秀的成績。
參考文獻
[1] 許哲豪,NTUST Edge AI Ch3-1 資料集建置與標註─資料集建置
https://omnixri.blogspot.com/p/ntust-edge-ai-ch3-1.html
[2] 雞雞與兔兔的工程世界, 淺談AIGC爆炸的時代 —AI繪圖 Stable Diffusion、Mid-Journey、DALL·E 2
https://medium.com/雞雞與兔兔的工程世界/淺談aigc爆炸的時代-ai繪圖-stable-diffusion-mid-journey-dall-e-2-4e0cf67afd8d
[3] Nvidia, How to Train an Object Detection Model for Visual Inspection with Synthetic Data
https://developer.nvidia.com/blog/how-to-train-an-object-detection-model-for-visual-inspection-with-synthetic-data/
[4] 許哲豪,【vMaker EDGE AI專欄 #02】 要玩AI前,先來認識數字系統
https://omnixri.blogspot.com/2023/02/vmaker-edge-ai-02-ai.html
本文同步發表在【台灣自造者 vMaker】


沒有留言:
張貼留言